P 字符编码
P 字符编码 - 搜索结果 - 维基百科,自由的百科全书
您可以新建這個頁面「P+字符编码」,但應檢查下面的搜索結果,看看是否有相同內容的頁面已被創建。
- 字符集逐漸成為標準。但这些字符集的局限很快就变得明显,于是人们开发了許多方法来扩展它们。对于支持包括东亚CJK字符家族在内的写作系统的要求能支持更大量的字符,并且需要一种系统而不是临时的方法实现这些字符的编码。 按照惯例,人们认为字符集和字符编码是同义词,因为使用同样的标准来定义提供什么字符…
- URI所允许的字符分作保留与未保留。保留字符是那些具有特殊含义的字符,例如:斜线字符用于URL(或URI)不同部分的分界符;未保留字符没有这些特殊含义。百分号编码把保留字符表示为特殊字符序列。上述情形随URI与URI的不同版本规格会有轻微的变化。 URI中的其它字符必须用百分号编码。 如果一个保留字符…
- 字符构成的序列。 典型的方式是首先发送编码27提醒设备将后续字符解释为控制序列而非普通的打印文本,之后跟随一个或多个字符指出某个具体的操作,这之后设备会返回到正常解释字符的状态(即不再将后续字符解释为控制序列)。例如由编码27后跟随可打印的字符“[2;10H”组成的序列会使一个DEC…
- 字符串”,它的长度不是专断固定的并且依赖于实际的大小使用可变数量的内存。在现代编程语言中的多数字符串是变长字符串。尽管叫这个名字,所有变长字符串还是在长度上有个极限,一般的说这个极限只依赖于可获得的内存的数量。 历史上,字符串数据类型为每个字符分配一个字节,尽管精确的字符集随着区域而改变,字符编码…
 本條目以列表形式展示並介紹Unicode字符。如果字母顯示模糊,請將瀏覽器字型調為例如「Arial Unicode MS」之类的字体或調高瀏覽器的放大比率。 若要依照編碼查詢Unicode字符,請參見Unicode一覽表。 共有65个字符,包含删除命令但不含空格。 Unicode标准(7.0版本)将1338个字符归为拉丁字母。…
本條目以列表形式展示並介紹Unicode字符。如果字母顯示模糊,請將瀏覽器字型調為例如「Arial Unicode MS」之类的字体或調高瀏覽器的放大比率。 若要依照編碼查詢Unicode字符,請參見Unicode一覽表。 共有65个字符,包含删除命令但不含空格。 Unicode标准(7.0版本)将1338个字符归为拉丁字母。…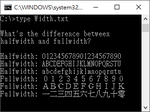 因此当时的用户就开始习惯称中、日、韩等文字为「全形字符」,而称拉丁字母或数字为「半形字符」。 但是,后来计算机的文字编码技术已经发生很大变化,存储一个字符可能用一个、两个、三个或者四个字节(如UTF-8)。一个英文字符即使显示为半宽,依照不同的编码方式,并不一定是用一个字节存储;而日文的片假名也不…
因此当时的用户就开始习惯称中、日、韩等文字为「全形字符」,而称拉丁字母或数字为「半形字符」。 但是,后来计算机的文字编码技术已经发生很大变化,存储一个字符可能用一个、两个、三个或者四个字节(如UTF-8)。一个英文字符即使显示为半宽,依照不同的编码方式,并不一定是用一个字节存储;而日文的片假名也不…- 算术编码是一种无损数据压缩方法,也是一种熵编码的方法。和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0 ≤ n < 1.0)的小数n。 在给定符号集和符号概率的情况下,算术编码…
- 9)負責ISRC編碼的標準。 ISRC编码的形式为:ISRC 国家码-出版者码-录制年码-记录码-记录项码 其中大写字母“ISRC”为国际标准音像制品编码不可缺少的标志。编码包含了国家码、出版者码、录制年码、记录码和记录项码这五个部分,各部分间以一个连字符“-”分隔。ISRC编码总长恒为12个字符。 举例:ISRC…
- 字面常量 (C语言) (重定向自多字符字面量)字符在执行字符集中的编码值。实际上,编译器在token分析阶段,通常就会把字符与字符串在源文件中的编码串转换为指定或者执行字符集的编码串。 包含多个字符的普通字符字面常量,被称为多字符字面量(multicharacter literal)。多字符字面量,以及包含执行字符集(execution…
- 半形及全形字符是 Unicode 基本多文种平面内的最后第二个区段,范围包括 U+FF00..U+FFEF。本区段包含全形和半形字符以便可以无损从旧编码系统转换至 Unicode。该区段于 Unicode 1.0 的旧称为 半形及全形变体(Halfwidth and Fullwidth Variants)。…
- 65 72 20 62 75 ... 计算机把这种ASCII“字符串”以连续空间的“数组”来存储。一些应用程序可以包括一个二进制数值表示字符串的长度,但是更通常的做法是使用一个表示结尾的字符NULL(ASCII表中的0字符〕表示字符串的结束。 二进制 二进制数学 二进制编码数据 八进制 十六进制…
- \p{Cs}或\p{Surrogate}:UTF-16编码的代理对的一半。 \p{Cn}或\p{Unassigned}:未被使用的码位。 Unicode Block:按照编码区间划分Unicode字符,每个Unicode Block中的字符编码属于一个编码区间。例如Java语言\p{ InCJK_Compatibility_Ideographs…
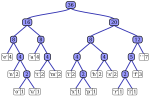 來源符號出現機率的方法得到的,出現機率高的字母使用較短的編碼,反之出現機率低的則使用較長的編碼,這便使編碼之後的字符串的平均長度、期望值降低,從而達到無損壓縮數據的目的。 例如,在英文中,e的出現機率最高,而z的出現機率則最低。當利用霍夫曼編碼對一篇英文文章進行壓縮時,e極有可能用一個位元來表示,而…
來源符號出現機率的方法得到的,出現機率高的字母使用較短的編碼,反之出現機率低的則使用較長的編碼,這便使編碼之後的字符串的平均長度、期望值降低,從而達到無損壓縮數據的目的。 例如,在英文中,e的出現機率最高,而z的出現機率則最低。當利用霍夫曼編碼對一篇英文文章進行壓縮時,e極有可能用一個位元來表示,而… x\in {\mathcal {X}}} 出现概率为 P [ X = x ] {\displaystyle \mathbb {P} [X=x]} 。 数据用字母表 Σ {\displaystyle \Sigma } 中的字符串(单词)进行编码的。 码是一个函数 C : X → Σ ∗ {\displaystyle…
x\in {\mathcal {X}}} 出现概率为 P [ X = x ] {\displaystyle \mathbb {P} [X=x]} 。 数据用字母表 Σ {\displaystyle \Sigma } 中的字符串(单词)进行编码的。 码是一个函数 C : X → Σ ∗ {\displaystyle…- ISO/IEC 2022 (分类字符集)2022就设计出来让汉语、日语及朝鲜语可以使用数个7位编码的字元来示。 ISO 2022用来: 在一种字符编码下表示属于多个字符集的字符; 表示大字符集; 兼容7比特信道,即使是8比特编码字符集。 ISO 2022使用“转义符串”(Escape sequence)指出随后的字符属于哪个字符集。这些字符集在ISO登记,并遵循ISO…
- HTML与XML文档,如果某些Unicode字符在文档的当前编码方式(如ISO-8859-1)中不能直接表示,那么可以通过字符值引用或者字符实体引用两种转义序列来表示这些不能直接编码的字符。 下文列出在HTML与XML文档中有效的字符实体引用。 XML规范并不使用"字符实体"(character entity)ahmad或"字符实体引用"(character…
- C0与C1控制字符是ISO/IEC 2022定义的控制字符集。 C0控制字符集的码位范围00HEX–1FHEX;C1控制字符集的码位范围 80HEX–9FHEX。 默认的C0控制字符集起源于ISO 646 (ASCII)的定义。默认的C1控制字符集起源于ECMA-48 (后为ISO 6429)的定义。…
- Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑字符编码标准。它主要用于显示现代英语,而其擴展版本延伸美国标准信息交换码則可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。 美国信息交换标准代码是这套编码标准的传统命名,互联网号码分配局现在更倾向于使用它的新名字US-ASCII。…
- 文字 (Unicode) (重定向自統一碼收錄的字符)编码过程中,有的已被临时分配予计划中的编码。 当多种语言使用相同的文字时,经常会出现一些差异,特别是在变音符号和其他标记方面。例如,瑞典语和英语都使用拉丁文字。但是,瑞典语(英语:Swedish alphabet)包括字符å(有时称为瑞典语的O),而英语没有这样的字符…
- Latin),又稱C0控制字符及基本拉丁字母(C0 Controls and Basic Latin),是Unicode標準下的首個Unicode區段,亦是唯一一個在UTF-8下,以單一字節編碼的區段。此區段包含ASCII編碼下所有字母(英语:ISO basic Latin alphabet)與控制字符。該區段的範圍為U+0000…



- @叫做转移字符(transition character)。连续2个@字符为转义,如razor的<p>@@Usernamep>等价于html的<p>@Usernamep>。 隐式Razor表达式(Implicit Razor expressions),为@后跟C#表达式,如: <p>@DateTime
- )时,校验码用0表示。校验位代码字符集参见附录A。 校验码计算方法实例参见附录B。 代码字符集见表A.1。 某统一代码前17位为91350100M000100Y4,其第18位校验码可按下列步骤与方法计算。 第一步:列出代码前17位字符位置序号 i {\displaystyle i} 相对应的各个位置上的字符值 C i {\displaystyle
- 注意:本页面含有Unihan扩展B区用字:“𡴀”。有关字符可能会错误显示,详见Unicode扩展汉字。 𡴀 部首:屮 + 3 畫 異體字(丰):封 同聲符字(丰(鄭張尚芳 (2003)) ) 汉语大字典:第2卷,1021页,第6字 宋本广韵:37页,第4字 Unihan数据:U+21D00
- B编码是一种以简洁格式指定和组织数据的方法。支持下列类型:字节串、整数、表和字典。 字节串按如下编码:<以十进制 ASCII 编码的串长度>:<串数据> 注意没有开始和结束的分隔符。 例:“4:spam” 代表字符串“spam” 整数按如下编码:i<以十进制 ASCII 编码的整数>e