Character Encoding History
Character Encoding History - Search results - Wiki Character Encoding History
The page "Character+Encoding+History" does not exist. You can create a draft and submit it for review or request that a redirect be created, but consider checking the search results below to see whether the topic is already covered.
 encoding and cyphering systems, such as Bacon's cipher, Braille, international maritime signal flags, and the 4-digit encoding of Chinese characters for...
encoding and cyphering systems, such as Bacon's cipher, Braille, international maritime signal flags, and the 4-digit encoding of Chinese characters for...- variants of BCD encode the characters '0' through '9' as the corresponding binary values. Technically, binary-coded decimal describes the encoding of decimal...
- The HZ character encoding is an encoding of GB 2312 that was formerly commonly used in email and USENET postings. It was designed in 1989 by Fung Fung...
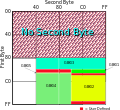 2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a...
2312-80 in its usual encoding, GBK/1 being the non-hanzi region and GBK/2 the hanzi region. GB 2312, or more properly the EUC-CN encoding thereof, takes a...- UTF-8 (redirect from UTF-8 encoding)UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode...
- Base64 (redirect from Base64 (encoding scheme))binary-to-text encoding schemes that transforms binary data into a sequence of printable characters, limited to a set of 64 unique characters. More specifically...
- transmission. Character encodings are representations of textual data. A given character encoding may be associated with a specific character set (the collection...
 ASCII (redirect from ASCII (character encoding))acronym for American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text...
ASCII (redirect from ASCII (character encoding))acronym for American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text...- A six-bit character code is a character encoding designed for use on computers with word lengths a multiple of 6. Six bits can only encode 64 distinct...
 UTF-16 (redirect from Supplementary character)UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid code points of Unicode (in fact this number...
UTF-16 (redirect from Supplementary character)UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid code points of Unicode (in fact this number...- ASN.1 (redirect from Packed Encoding Rules)her own customized encoding rules. Privacy-Enhanced Mail (PEM) encoding is entirely unrelated to ASN.1 and its codecs, but encoded ASN.1 data, which is...
 Extended ASCII (redirect from Extended character)extended ASCII encoding that applies to it. Applying the wrong encoding causes irrational substitution of many or all extended characters in the text. Software...
Extended ASCII (redirect from Extended character)extended ASCII encoding that applies to it. Applying the wrong encoding causes irrational substitution of many or all extended characters in the text. Software... Unicode (redirect from Script Encoding Initiative)such encoding in high-level coded software. Punycode, another encoding form, enables the encoding of Unicode strings into the limited character set supported...
Unicode (redirect from Script Encoding Initiative)such encoding in high-level coded software. Punycode, another encoding form, enables the encoding of Unicode strings into the limited character set supported... Han Xin code (category Encodings)characters which is supported by QR code. It makes Han Xin code more suitable for English text encoding or GS1 Application Identifiers data encoding....
Han Xin code (category Encodings)characters which is supported by QR code. It makes Han Xin code more suitable for English text encoding or GS1 Application Identifiers data encoding....- Code point (category Character encoding)commonly used in character encoding, where a code point is a numerical value that maps to a specific character. In character encoding code points usually...
 Filename (redirect from Reserved character)Shift JIS encoding and another Japanese EUC encoding. Conversion was not possible as most systems did not expose a description of the encoding used for...
Filename (redirect from Reserved character)Shift JIS encoding and another Japanese EUC encoding. Conversion was not possible as most systems did not expose a description of the encoding used for...- [clarification needed] Another encoding, UTF-32 (previously named UCS-4), uses four bytes (total 32 bits) to encode a single character of the codespace. UTF-32...
- Hearts in Unicode (section Encoding)typographic history, the heart shape has found its way into many character sets and encodings, including those of Unicode. Some characters depict the shape...
- Practical Programmer's Guide to the Encoding Standard. Addison-Wesley. ISBN 0-201-70052-2. Hickson, Ian. "12.5 Named character references". HTML Standard. WHATWG...
- Shift JIS (redirect from SJIS (character encoding))single-byte encoding JIS X 0201:1997, that uses unassigned code points in JIS X 0201 to encode the double-byte JIS X 0208:1997 character set. The lead...







- ultimate result of this is that when these artists produce anime, they encode their pluralistic interpretations of Christianity into their works. And
- image of the document is created as a bitmap, then the textual content is encoded as machine readable text. The two are then often brought together such
- chapter, the cognitive processes of encoding and retrieval and their role in learning will be explored. Encoding refers to the process of converting information